
TL;DR · resumen ejecutivo
¿Qué vas a encontrar en este artículo?
Si tu web no aparece donde debería, muchas veces no es porque “falten keywords” ni porque el contenido sea malo: es porque el buscador ni siquiera está viendo lo importante. Y ahí es donde entra el crawler. Mientras tú piensas en leads y en cerrar oportunidades, el rastreador decide qué páginas descubre, cuáles visita de verdad y cuáles se quedan olvidadas en un rincón de tu arquitectura....
Si tu web no aparece donde debería, muchas veces no es porque “falten keywords” ni porque el contenido sea malo: es porque el buscador ni siquiera está viendo lo importante. Y ahí es donde entra el crawler. Mientras tú piensas en leads y en cerrar oportunidades, el rastreador decide qué páginas descubre, cuáles visita de verdad y cuáles se quedan olvidadas en un rincón de tu arquitectura.
Según BrightEdge (2025), el tráfico orgánico representa el 53,3% de todo el tráfico web, consolidándose como el canal de adquisición más importante.
En CRONUTS.DIGITAL trabajamos el SEO con una idea muy simple: si tu web no se deja rastrear bien, lo demás se convierte en maquillaje. En este artículo vas a entender qué es un crawler, cómo funciona de verdad en el día a día de un proyecto B2B en España, qué señales técnicas lo ayudan (o lo frenan) y cómo convertir el rastreo en un aliado para ganar visibilidad sin depender de “mil cambios” que luego no mueven el marcador.
¿Qué es un crawler SEO?
Un crawler de SEO (también llamado bot, spider o robot de rastreo) es un programa automatizado que recorre páginas web siguiendo enlaces y recopila información para que un motor de búsqueda pueda descubrir, entender y actualizar lo que hay en un sitio. Es decir:
Si tu web no se deja rastrear bien, el resto del SEO es maquillaje. Hemos visto proyectos donde un robots.txt mal configurado dejaba fuera el 40% de las URLs de negocio. Un crawler no perdona errores técnicos: los ignora.
Albert Puig Navàs, CEO de CRONUTS.DIGITAL
Qué hace exactamente un crawler
Cuando un crawler llega a una web, suele:
- Descubrir URLs: entra por una URL (home, sitemap, enlaces externos) y va encontrando nuevas páginas a través de enlaces internos.
- Leer el contenido y recursos: analiza HTML, títulos, encabezados, texto, datos estructurados, canonical, hreflang, etc. Según el caso, también intenta cargar recursos como CSS/JS para interpretar la página.
- Detectar señales técnicas: estado HTTP (200, 301, 404…), redirecciones, cadenas, errores del servidor, tiempos de respuesta.
- Respetar reglas de rastreo: tiene en cuenta
robots.txt, meta robots (noindex,nofollow), cabeceras (X-Robots-Tag) y otros límites. - Enviar la información para indexación: el rastreo no garantiza indexación; primero se descubre y se analiza, y luego el buscador decide si indexa.
Por qué importa en SEO
El crawler condiciona tres cosas clave:
- Descubrimiento: si no encuentra una URL, esa página prácticamente “no existe” para el buscador.
- Eficiencia: el presupuesto de rastreo (crawl budget) es limitado; arquitectura, enlaces y performance ayudan a que el bot invierta su tiempo en lo importante.
- Calidad de indexación: si el crawler ve contenido pobre, duplicado, bloqueado o confuso (JS mal renderizado, canonical incorrecto), la indexación y el ranking se resienten.

Diferencia rápida: crawler vs indexación vs ranking
Ranking: decide en qué posición aparece cada página para una búsqueda concreta.
Crawler: visita y recopila.
Indexación: guarda/organiza lo rastreado para poder mostrarlo en resultados.
¿Cómo afecta a mi web?
Un crawler determina qué URLs descubre, con qué frecuencia las visita y qué señales técnicas y de contenido interpreta. En la práctica impacta en:
- Indexación: si una URL no se rastrea (o se rastrea mal), suele indexarse tarde o no indexarse.
- Visibilidad orgánica: páginas importantes que el bot visita poco o encuentra con errores pierden oportunidades de posicionar.
- Consumo de recursos: un rastreo ineficiente (muchas URLs inútiles, parámetros, duplicados) hace que el bot “gaste” visitas donde no toca.
- Diagnóstico técnico: errores (4xx/5xx), redirecciones largas, tiempos de carga altos o bloqueos pueden reducir el rastreo y la calidad de lo que se procesa.
¿Qué hago si tengo problemas de crawling?
Aborda el problema en este orden (de lo más bloqueante a lo más optimizable):
- Comprueba si el bot puede acceder
- Revisa
robots.txty reglasDisallow. - Revisa meta robots / cabeceras:
noindex,nofollow,X-Robots-Tag. - Verifica que no haya bloqueos por WAF/CDN, rate limits o geobloqueo.
- Identifica errores y cuellos de botella
- Errores 5xx (servidor), 4xx (URLs rotas) y timeouts.
- Redirecciones en cadena o bucles (301→301→200).
- Lentitud: TTFB alto y respuesta inestable.
- Asegura el descubrimiento de URLs importantes
- Sitemap XML actualizado (solo URLs canónicas y 200).
- Arquitectura y enlazado interno: que las páginas clave no dependan de búsquedas internas ni de enlaces ocultos.
- Evita páginas huérfanas (sin enlaces internos).
- Reduce duplicados y ruido
- Parámetros y facetas sin control (filters, sort, tracking).
- Paginaciones infinitas o calendarios que generan miles de URLs.
- Canonical mal configurado que confunde al bot.
- Valida con datos
- En Google Search Console: informes de indexación, estadísticas de rastreo, ejemplos de URLs afectadas.
- Logs del servidor: qué bots entran, qué rastrean, con qué frecuencia y qué códigos reciben.
- Crawl con herramienta SEO para reproducir el problema en tu arquitectura.
¿Cómo optimizo el crawl budget?
El crawl budget determina cuántas páginas de tu web rastrea Google en un período dado. Una web con miles de URLs de baja calidad desperdicia su crawl budget y puede dejar sin indexar páginas de negocio críticas. Optimízalo con estas palancas:
1) Prioriza lo importante (señales de “esto merece rastreo”)
- Enlaza con fuerza desde navegación, categorías, hubs y contenidos de alto tráfico.
- Usa una estructura clara (profundidad baja para páginas clave).
- Mantén sitemaps limpios y segmentados (por tipo de contenido).
2) Elimina desperdicio (menos URLs inútiles = más presupuesto para las buenas)
- Controla facetas y parámetros: restringe combinaciones indexables y bloquea el resto (según el caso, con
noindex, canonicals, reglas enrobots.txto gestión de parámetros). - Evita generar URLs infinitas (búsquedas internas indexables, calendarios, filtros sin límites).
- Corrige duplicados por http/https, www/no-www, slash/no-slash, mayúsculas, etc.
3) Mejora la salud técnica (más capacidad de rastreo real)
- Reduce 5xx/4xx y cadenas de redirección.
- Mejora rendimiento y estabilidad del servidor (menos timeouts, mejor TTFB).
- Usa caché/CDN con cuidado para no bloquear bots.
4) Alinea indexación con negocio
- Asegura que landings de conversión, categorías y contenidos estratégicos sean:
- 200, canónicas, enlazadas y presentes en sitemap.
- Saca del camino lo que no aporta: tags vacíos, paginaciones sin valor, thin content.
Pros y contras de las soluciones típicas
- Bloquear en robots.txt: ahorra rastreo, pero no “borra” URLs ya conocidas y puede dificultar que el bot vea canonicals/contenido.
- Noindex: útil para limpiar índice, pero la URL puede seguir rastreándose un tiempo; no ahorra tanto como un bloqueo.
- Canonical: ayuda con duplicados, pero el bot igual rastrea las variantes; es más “señal” que “corte”.
- Mejor enlazado interno + sitemaps: suele ser lo más limpio y sostenible; requiere trabajo de arquitectura.
Cómo funciona un crawler en la práctica

Un crawler no “lee” una web como una persona. Opera con reglas y prioridades. En general, hace esto:
- Descubre URLs (enlaces internos, sitemaps, enlaces externos).
- Decide si las visita (según señales y límites).
- Solicita la página al servidor.
- Recoge HTML, recursos y señales.
- Sigue enlaces que encuentra (si le interesa y puede).
Y aquí viene la parte incómoda: no rastrea todo lo que existe. Rastrea lo que puede y lo que considera que vale la pena rastrear.
Crawl budget: el presupuesto que te pone el buscador (aunque no lo veas)
El “crawl budget” se entiende como la cantidad de rastreo que un buscador dedica a tu sitio en un periodo. Depende, sobre todo, de:
- capacidad del servidor para responder sin errores ni lentitud,
- interés percibido del sitio (valor de las URLs, frescura, popularidad),
- arquitectura interna (cómo de fácil es llegar a las páginas relevantes).
Si tu web genera miles de URLs poco útiles, el crawler malgasta visitas en basura y llega tarde (o nunca) a lo que sí importa.
Lo que un crawler “odia” (y lo que lo empuja a pasar de ti)
Un crawler no siente nada, pero su comportamiento lo deja claro:
- errores 5xx o caídas,
- redirecciones en cadena,
- URLs infinitas con parámetros,
- contenido duplicado sin canonicals claros,
- páginas pesadas que tardan en responder,
- trampas de calendario y paginaciones mal resueltas.
Si tu web se parece a eso, no estás compitiendo por SEO: estás compitiendo por sobrevivir al rastreo.
Señales técnicas que influyen en el rastreo

Robots.txt: el portero, no el editor
El archivo robots.txt sirve para indicar qué partes pueden rastrearse. No “borra” URLs, no desindexa por sí mismo y no arregla duplicados. Bien usado, ayuda a que el crawler no pierda tiempo donde no debe (por ejemplo, zonas internas sin valor orgánico).
Mal usado, bloquea secciones clave y luego llegan las dudas: “¿por qué no aparece mi página en Google?”. Porque no la dejaste entrar. Fácil.
Meta robots: el semáforo dentro de la página
En una página concreta puedes decir:
index, follow(lo habitual),noindex(puede rastrearla, pero no quieres que se indexe),nofollow(no quieres pasar señal a enlaces, con matices).
Importante: si bloqueas por robots.txt, el crawler no llega a leer el meta robots de esa página. O sea, si tu objetivo es noindex, lo normal es no bloquear por robots.txt y usar el meta robots.
Sitemap.xml: el mapa que sí conviene darle
Un sitemap no garantiza indexación, pero sí mejora el descubrimiento. Lo más útil es que contenga:
- URLs canónicas,
- páginas que de verdad quieres posicionar,
- fechas de última modificación (si se gestionan bien),
- una estructura limpia por tipos (servicios, blog, recursos, etc.).
Para un crawler, un sitemap bien mantenido es una pista directa: “esto es lo que me interesa que mires”.
Enlazado interno: donde se ganan (o se pierden) semanas
Si una página importante está a 6 clics de la home, con menús confusos y enlaces rotos, el crawler la tratará como secundaria.
Un enlazado interno fuerte:
- reduce profundidad,
- refuerza clusters temáticos,
- reparte autoridad,
- acelera descubrimiento.
En B2B, esto se nota especialmente en páginas de servicio, casos de éxito y recursos de conversión.
Renderizado: cuando el crawler se encuentra con JavaScript

Muchas webs modernas dependen de JavaScript para mostrar contenido. El problema: el rastreo y el renderizado no siempre van de la mano.
Qué pasa si el contenido “aparece” tarde
Si el texto principal, enlaces o datos clave se generan después mediante scripts, el crawler puede:
- ver un HTML casi vacío,
- no descubrir enlaces relevantes,
- indexar una versión incompleta.
Solución típica: asegurar renderizado del lado servidor o pre-render para páginas orgánicas críticas, o al menos que el HTML inicial incluya lo esencial.
Riesgos comunes en B2B
- landings con contenido cargado por componentes que no dejan rastro en el HTML inicial,
- catálogos que dependen de filtros y parámetros infinitos,
- páginas que requieren interacción para mostrar información.
Si tu web depende de eso para “contar” qué vendes, el crawler puede no enterarse. Y si no se entera, no existes.
Duplicidad y canónicas: el orden que el crawler necesita
En B2B hay duplicidad por naturaleza: servicios similares, soluciones por sector, fichas repetidas, paginaciones. No pasa nada… si lo controlas.
Canonical: la forma de decir “esta es la versión buena”
La etiqueta canonical indica cuál es la URL principal cuando hay varias que se parecen. Para un crawler, esto reduce confusión y ayuda a consolidar señales.
Errores típicos:
- canonicals que apuntan a una URL que no devuelve 200,
- canonicals contradictorias con redirecciones,
- canonicals que cambian según parámetros sin lógica.
Parámetros: el agujero negro del rastreo
Filtros, ordenaciones, tracking, paginación… Si cada combinación crea una URL rastreable, el crawler se puede pasar el día dando vueltas.
Aquí manda una decisión: qué parámetros tienen valor orgánico y cuáles deben quedarse fuera del rastreo y/o de la indexación. Si no lo decides tú, lo decide el buscador, y suele decidir mal.
Respuesta del servidor: el punto donde el crawler se rinde
El rastreo también es un tema de infraestructura:
- tiempo de respuesta alto,
- picos de errores,
- limitaciones agresivas,
- CDN mal configurado,
- redirecciones innecesarias.
Cuando un crawler encuentra demasiadas respuestas problemáticas, reduce frecuencia y prioriza menos. Es como si tu web le dijera: “vuelve otro día”. Y ese “otro día” puede coincidir con tu campaña, tu lanzamiento o tu mejor contenido.
Códigos de estado que conviene tener bajo control
- 200: correcto.
- 301/302: redirección (bien, si tiene sentido y no se encadena).
- 404: no encontrado (aceptable en casos puntuales, peligroso si se dispara).
- 410: eliminado de forma intencional (útil para limpiezas).
- 5xx: error del servidor (lo peor para el rastreo).
Si tu web acumula 5xx, el crawler baja la intensidad. No hay épica aquí: hay mantenimiento.
Cómo saber si un crawler está rastreando lo que te interesa
Sin entrar en promesas mágicas, hay señales claras para auditar la situación:
Logs del servidor: la verdad sin maquillaje
Los logs muestran:
- qué bots visitan,
- qué URLs tocan,
- con qué frecuencia,
- qué respuesta reciben,
- a qué hora rastrean más.
Esto permite detectar si el crawler se está gastando el tiempo en URLs poco útiles, si choca con errores o si ignora secciones clave.
Google Search Console: señales accionables
Search Console ayuda a ver:
- cobertura (indexadas, excluidas, errores),
- sitemaps y URLs descubiertas,
- problemas de rastreo,
- inspección de URL (qué ve el buscador y cómo la procesa).
La combinación de logs + Search Console suele dar un diagnóstico muy sólido.
Problemas típicos con crawler que frenan el SEO en empresas

Migraciones sin control del rastreo
Cambiar URLs, CMS o arquitectura sin plan suele producir:
- pérdida de páginas indexadas,
- redirecciones mal hechas,
- duplicidad temporal,
- caída de rastreo en zonas clave.
Aquí el crawler se comporta como un auditor: si ve caos, reduce confianza.
Contenido “huérfano”
Páginas que existen, pero nadie enlaza. Si no están bien enlazadas internamente ni en sitemap, el crawler las descubre tarde o no las descubre.
Paginaciones y listados mal resueltos
Listados de recursos o productos/servicios con paginación que genera URLs infinitas sin prioridad. Resultado: el crawler entra, se pierde, y te deja sin cobertura donde más quieres.
Bloqueos accidentales
Un robots.txt o una etiqueta noindex puesta en el momento equivocado puede tumbar una sección entera. Y lo peor: a veces nadie lo nota hasta que el tráfico cae.
Cómo convertir el rastreo en una ventaja competitiva (sí, ventaja)
Esto va de foco: guiar al crawler hacia lo que vende y alejarlo de lo que distrae.
Arquitectura pensada para SEO, no para “quedar bonita”
- jerarquía clara,
- categorías con sentido,
- enlaces internos que llevan a páginas de negocio,
- eliminación de basura indexable.
Higiene de URLs
- canónicas coherentes,
- redirecciones limpias,
- parámetros controlados,
- paginación con intención.
Contenido que merece ser rastreado
Si publicas 30 posts que nadie enlaza y que repiten lo mismo, el crawler aprende que tu web aporta poco. Si publicas menos, pero mejor conectado y con utilidad real, el rastreo se vuelve más inteligente.
En B2B, esto se nota cuando el blog deja de ser “relleno” y pasa a ser soporte de captación: guías, comparativas honestas, casos de uso, respuestas a objeciones.
¿Cómo afecta la IA al SEO?

Si todavía estás enfocando el SEO como si todo fuese “subir posiciones en Google y ya”, vas a llegar tarde. La IA ha cambiado el tablero porque cada vez más búsquedas no acaban en diez enlaces azules, sino en una respuesta ya masticada. Y ahí entran dos siglas que vas a ver hasta en la sopa: AEO y GEO (Generative Engine Optimization).
AEO: cuando tu objetivo es ser “la respuesta”, no “un resultado”
AEO (Answer Engine Optimization) es optimizar para motores que responden, no solo para motores que listan resultados. Piensa en:
- respuestas directas en buscadores,
- paneles de información,
- resúmenes que aparecen antes de que el usuario haga clic,
- preguntas frecuentes que se contestan solas.
¿Qué significa esto en la práctica? Que tu contenido tiene que dejarle al buscador el trabajo fácil. Si el sistema entiende rápido qué preguntas respondes y con qué autoridad, tienes más opciones de ganar visibilidad sin depender de que el usuario entre en tu web.
En B2B esto es oro, porque muchas búsquedas son de evaluación: “qué es”, “cómo funciona”, “diferencias entre”, “mejor opción para”, “ventajas y riesgos”. Si tu página responde con claridad, estructura y contexto, te conviertes en la fuente que el motor usa para construir la respuesta.
GEO: optimizar para motores generativos sin perder el control del mensaje
GEO (Generative Engine Optimization) va un paso más allá: no se trata de aparecer en un snippet, sino de aparecer dentro de la respuesta generada por un buscador con IA.
Aquí hay un cambio de mentalidad:
- antes competías por clics,
- ahora compites por “ser citado”, “ser usado”, “ser referencia”.
Y sí, esto genera FOMO real, porque si tu competencia se cuela como fuente en respuestas generadas y tú no, hay una parte del mercado que ni te ve.
Qué tiene que tener tu contenido para aparecer en buscadores de IA
Los motores generativos suelen construir respuestas a partir de señales similares a las del SEO clásico, pero con un filtro extra: necesitan fragmentos fiables, claros y reutilizables. Para aumentar probabilidades:
Estructura que se entiende a la primera
- H2 y H3 bien planteados.
- Definiciones directas.
- Secciones que respondan preguntas concretas sin rodeos.
Si un sistema puede extraer un párrafo y que tenga sentido por sí solo, vas mejor.
Contexto y especificidad útil (sin humo)
- términos bien explicados,
- relaciones claras entre conceptos,
- pasos o criterios de decisión cuando toca.
No es escribir más por escribir. Es escribir para que el contenido “se pueda usar” en una respuesta.
Autoridad que no depende de prometer
En B2B, la IA tiende a favorecer contenidos que parecen hechos por alguien que sabe de qué habla, no por alguien que repite definiciones. Se nota en:
- claridad al explicar,
- consistencia del lenguaje,
- ausencia de contradicciones,
- profundidad en puntos clave.
AEO y GEO no sustituyen al SEO: lo obligan a madurar
El SEO técnico y el contenido siguen siendo la base. Lo que cambia es el destino:
- antes el objetivo era atraer clics,
- ahora también es ganar presencia aunque el clic no llegue.
Y aquí viene la parte estratégica: si tu marca aparece en respuestas generadas, aunque el usuario no entre, te está viendo. Te está metiendo en su shortlist mental. Eso, en B2B, es medio funnel hecho.
Cómo conecta esto con el rastreo y el crawler
Un detalle importante: para que un buscador con IA use tu contenido, primero tiene que acceder a él. Si el crawler no rastrea bien tus páginas, si tu contenido clave está oculto tras renderizados complejos o si tus URLs se pierden en una arquitectura caótica, no hay AEO ni GEO que valga.
La IA no es magia: bebe de lo que puede encontrar, entender y considerar confiable. Si tu web no está preparada para que la rastreen y la interpreten bien, estás dejando escapar la nueva visibilidad justo cuando se está repartiendo.
Cómo funciona Googlebot
A continuación las diferentes fases:
Fase 1 — Descubrimiento de URLs
Googlebot encuentra nuevas páginas y actualizaciones a partir de varias fuentes:
- Enlaces internos: menús, categorías, módulos de contenido relacionado, breadcrumbs. Cuanto más cerca estén las URLs clave de la home (menos profundidad), antes suelen descubrirse.
- Sitemaps XML: sirven como guía de URLs prioritarias, siempre que estén bien curados (canónicas, 200, indexables).
- Enlaces externos: menciones y backlinks ayudan a descubrir y recrawlear contenido, sobre todo si el sitio tiene poca autoridad interna o está poco conectado.
- Señales de recrawl: cambios detectados por cabeceras, patrones históricos de actualización y popularidad del contenido.
Puntos que suelen bloquear el descubrimiento:
- Páginas sin enlaces internos (huérfanas).
- Arquitecturas con demasiados niveles, paginaciones profundas o facetas que “tapan” rutas relevantes.
- Dependencia de acciones de usuario (búsqueda interna, filtros sin URLs limpias) para acceder a contenido.
Fase 2 — Rastreo y renderizado
Una vez Googlebot decide visitar una URL, realiza dos procesos que conviene separar:
- Rastreo (fetch): solicita la página y recibe una respuesta HTTP.
- Si hay errores (5xx), timeouts o demasiadas redirecciones, el rastreo se degrada y se pospone.
- Si hay bloqueos (robots, noindex, X-Robots-Tag), condiciona lo que puede procesar después.
- Renderizado: intenta interpretar la página como un navegador para ver el contenido real que se muestra al usuario.
- Si el contenido depende de JavaScript, Google necesita ejecutar recursos (JS/CSS) y esperar a que el DOM final esté disponible.
- Si recursos críticos están bloqueados o fallan (JS/CSS/API), puede “ver” una página incompleta.
- Si el renderizado es pesado (muchas llamadas, SSR mal implementado, hydration lenta), puede retrasar el procesamiento.
Qué busca Googlebot aquí (a nivel SEO técnico):
- Contenido principal y su coherencia con el HTML inicial.
- Enlaces internos que descubre durante el render.
- Señales de control: canonical, hreflang, datos estructurados, meta robots, estado de indexabilidad.
Fase 3 — Indexación
Tras rastrear y, cuando aplica, renderizar, Google decide qué hacer con esa URL:
- Selección de canónica: determina cuál es la versión principal si hay duplicados o variantes (parámetros, facetas, versiones similares). Si tu canonical es inconsistente, Google puede ignorarlo y elegir otra.
- Evaluación de calidad y unicidad: páginas con poco valor, duplicadas o generadas en masa pueden quedarse fuera del índice o caer en estados de “descubierta pero no indexada”.
- Procesamiento de señales: estructura del contenido, datos estructurados, idioma, intención, enlaces internos y externos, y otros factores que ayudan a clasificar y mostrar la página en resultados.
- Actualización del índice: la URL puede entrar, salir o actualizarse en función de cambios del contenido, autoridad, rendimiento y comportamiento del rastreo.
Importante: rastreo no equivale a indexación. Una URL puede ser rastreada muchas veces y seguir sin indexarse si Google concluye que no aporta valor, es duplicada, o tiene señales contradictorias.
Según BrightEdge (2025), el tráfico orgánico representa el 53,3% de todo el tráfico web, consolidándose como el canal de adquisición más importante.
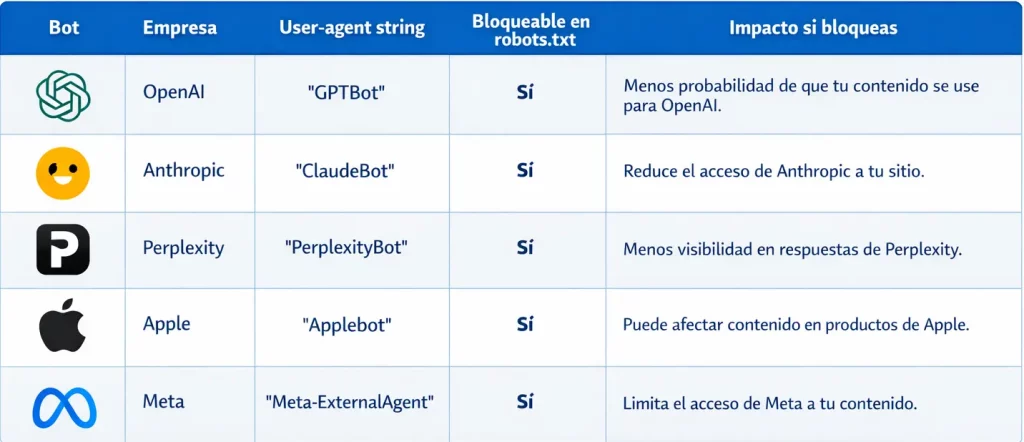
Crawlers de IA actuales: GPTBot, ClaudeBot y Perplexitybot
Gestionar correctamente el acceso de GPTBot, ClaudeBot y PerplexityBot en tu robots.txt define si tu contenido aparece como fuente en las respuestas de los motores de IA. Es el nuevo SEO técnico.
Qué hace cada crawler de IA en tu web
GPTBot (OpenAI)
- Rastreа páginas públicas para recopilar contenido que puede contribuir al entrenamiento/mejora de modelos.
- Se gestiona mediante reglas en
robots.txtpara ese user-agent.
ClaudeBot (Anthropic)
- Rastreа contenido público para mejorar utilidad y seguridad de los modelos (potencialmente con fines de entrenamiento).
- Anthropic indica que opera con varios robots y que puedes controlar su acceso con
robots.txt.
PerplexityBot (Perplexity)
- Está orientado a descubrir e indexar sitios para los resultados de búsqueda de Perplexity y enlazar a las fuentes.
- Perplexity especifica que no se usa para rastrear contenido destinado a modelos fundacionales.
Implicación GEO (para marketing)
- Permitir estos bots puede aumentar la probabilidad de aparición y cita de tu contenido en experiencias generativas o buscadores con respuestas, pero a cambio asumes más exposición (copyright, paywalls, contenido propietario) y posible carga adicional en servidor. La decisión suele ser por secciones, no “todo o nada”.
Cómo gestionar el acceso de los crawlers de IA con robots.txt
La forma más directa es definir reglas por User-agent en robots.txt. Ejemplos típicos:
# Bloquear GPTBot (OpenAI)
User-agent: GPTBot
Disallow: /# Bloquear ClaudeBot (Anthropic)
User-agent: ClaudeBot
Disallow: /# Bloquear PerplexityBot (Perplexity)
User-agent: PerplexityBot
Disallow: /
Si prefieres permitir solo una carpeta (modelo “allowlist”), puedes hacer lo contrario:
User-agent: GPTBot
Disallow: /
Allow: /blog/User-agent: ClaudeBot
Disallow: /
Allow: /blog/User-agent: PerplexityBot
Disallow: /
Allow: /blog/
Notas prácticas para webmasters:
- Perplexity documenta explícitamente las directivas para PerplexityBot y advierte que los cambios pueden tardar un tiempo en reflejarse.
- OpenAI describe sus crawlers y el control mediante
robots.txtpara GPTBot. - Anthropic explica el propósito de ClaudeBot y el control de acceso vía
robots.txt.
Si quieres, te lo adapto a tu caso con una política simple: qué permitir, qué bloquear (por ejemplo, /checkout/, /mi-cuenta/, filtros con parámetros, contenidos de pago) y cómo validarlo con logs.
En auditorías técnicas internas de CRONUTS.DIGITAL durante 2025, detectamos que aprox. 55% de los proyectos tenían señales claras de desperdicio de crawl budget que frenaban la indexación: parámetros indexables, paginaciones sin control y duplicidades por filtros, con un patrón repetido de URLs rastreadas sin valor frente a URLs de negocio que tardaban más en entrar o actualizarse en el índice. Herramientas utilizadas: Screaming Frog y Google Search Console.
Preguntas frecuentes
Lo que CMOs y directores nos preguntan.
8 dudas concretas con respuesta accionable en ≤ 80 palabras · formato óptimo para AI Overviews.


